
NVIDIA NeMo Framework

Specifikationer
- Produktnamn: NVIDIA NeMo Framework
- Berörda plattformar: Windows, Linux, macOS
- Berörda versioner: Alla versioner före 24
- Säkerhetssårbarhet: CVE-2025-23360
- Baspoäng för riskbedömning: 7.1 (CVSS v3.1)
Produktanvändningsinstruktioner
Installation av säkerhetsuppdatering:
För att skydda ditt system, följ dessa steg:
- Ladda ner den senaste versionen från NeMo-Framework-Launcher Releases-sidan på GitHub.
- Gå till NVIDIA Product Security för mer information.
Säkerhetsuppdateringsdetaljer:
Säkerhetsuppdateringen åtgärdar en sårbarhet i NVIDIA NeMo Framework som kan leda till kodexekvering och data tampäring.
Programuppgradering:
Om du använder en tidigare filialversion rekommenderar vi att du uppgraderar till den senaste filialversionen för att lösa säkerhetsproblemet.
Överview
NVIDIA NeMo Framework är ett skalbart och molnbaserat generativt AI-ramverk byggt för forskare och utvecklare som arbetar med Stora språkmodeller, Multimodal och Tal AI (till exempel Automatisk taligenkänning och Text-till-tal). Det gör det möjligt för användare att effektivt skapa, anpassa och distribuera nya generativa AI-modeller genom att utnyttja befintlig kod och förutbildade modellkontrollpunkter.
Installationsinstruktioner: Installera NeMo Framework
NeMo Framework ger end-to-end-stöd för att utveckla stora språkmodeller (LLM) och multimodala modeller (MM). Det ger flexibiliteten att användas på plats, i ett datacenter eller med din föredragna molnleverantör. Det stöder även körning i SLURM- eller Kubernetes-aktiverade miljöer.

Datakurering
NeMo-kurator [1] är ett Python-bibliotek som innehåller en uppsättning moduler för datautvinning och syntetisk datagenerering. De är skalbara och optimerade för GPU:er, vilket gör dem idealiska för att kurera naturliga språkdata för att träna eller finjustera LLM:er. Med NeMo Curator kan du effektivt extrahera högkvalitativ text från omfattande råmaterial web datakällor.
Utbildning och anpassning
NeMo Framework tillhandahåller verktyg för effektiv utbildning och anpassning av LLMs och multimodala modeller. Den innehåller standardkonfigurationer för konfiguration av datorkluster, datanedladdning och modellhyperparametrar, som kan justeras för att träna på nya datamängder och modeller. Förutom förträning stöder NeMo tekniker för både övervakad finjustering (SFT) och PEFT (Parameter Efficient Fine-Tuning) som LoRA, Ptuning och mer.
Två alternativ finns tillgängliga för att starta träning i NeMo – med hjälp av NeMo 2.0 API-gränssnittet eller med NeMo Run.
- Med NeMo Run (rekommenderas): NeMo Run tillhandahåller ett gränssnitt för att effektivisera konfiguration, exekvering och hantering av experiment över olika datormiljöer. Detta inkluderar att starta jobb på din arbetsstation lokalt eller på stora kluster – både SLURM-aktiverade eller Kubernetes i en molnmiljö.
- Förträning & PEFT Snabbstart med NeMo Run
- Använda NeMo 2.0 API: Denna metod fungerar bra med en enkel installation som involverar små modeller, eller om du är intresserad av att skriva din egen anpassade dataladdare, träna loopar eller byta modelllager. Det ger dig mer flexibilitet och kontroll över konfigurationer och gör det enkelt att utöka och anpassa konfigurationer programmatiskt.
-
Trasnabbstart med NeMo 2.0 API
-
Migrerar från NeMo 1.0 till NeMo 2.0 API
-
Inriktning
- NeMo-Aligner [1] är en skalbar verktygslåda för effektiv modellanpassning. Verktygslådan har stöd för toppmoderna modellanpassningsalgoritmer som SteerLM, DPO, Reinforcement Learning from Human Feedback (RLHF) och mycket mer. Dessa algoritmer gör det möjligt för användare att anpassa språkmodeller för att vara säkrare, ofarliga och användbara.
- Alla NeMo-Aligner-kontrollpunkter är korskompatibla med NeMo-ekosystemet, vilket möjliggör ytterligare anpassning och implementering av slutledningar.
Steg-för-steg arbetsflöde av alla tre faserna av RLHF på en liten GPT-2B-modell:
- SFT utbildning
- Belöna modellträning
- PPO utbildning
Dessutom visar vi stöd för olika andra nya inriktningsmetoder:
- DPO: en lätt inriktningsalgoritm jämfört med RLHF med en enklare förlustfunktion.
- Självspel Finjustering (SPIN)
- SteerLM: en teknik baserad på konditionerad SFT, med styrbar effekt.
Se dokumentationen för mer information: Uppriktningsdokumentation
Multimodala modeller
- NeMo Framework tillhandahåller optimerad programvara för att träna och distribuera toppmoderna multimodala modeller inom flera kategorier: Multimodala språkmodeller, Vision-Language Foundations, Text-to-Image-modeller och bortom 2D-generering med hjälp av Neural Radiance Fields (NeRF).
- Varje kategori är designad för att tillgodose specifika behov och framsteg inom området, genom att utnyttja banbrytande modeller för att hantera ett brett utbud av datatyper, inklusive text, bilder och 3D-modeller.
Notera
Vi migrerar stöd för multimodala modeller från NeMo 1.0 till NeMo 2.0. Om du vill utforska den här domänen under tiden, se dokumentationen för NeMo 24.07 (föregående) utgåva.
Utplacering och slutledning
NeMo Framework tillhandahåller olika vägar för LLM-inferens, som tillgodoser olika distributionsscenarier och prestandabehov.
Distribuera med NVIDIA NIM
- NeMo Framework integreras sömlöst med modelldistributionsverktyg på företagsnivå genom NVIDIA NIM. Denna integration drivs av NVIDIA TensorRT-LLM, vilket säkerställer optimerad och skalbar slutledning.
- För mer information om NIM, besök NVIDIA webplats.
Implementera med TensorRT-LLM eller vLLM
- NeMo Framework erbjuder skript och API:er för att exportera modeller till två inferensoptimerade bibliotek, TensorRT-LLM och vLLM, och för att distribuera den exporterade modellen med NVIDIA Triton Inference Server.
- För scenarier som kräver optimerad prestanda kan NeMo-modeller utnyttja TensorRT-LLM, ett specialiserat bibliotek för att accelerera och optimera LLM-inferens på NVIDIA GPU:er. Denna process innebär att NeMo-modeller konverteras till ett format som är kompatibelt med TensorRT-LLM med hjälp av modulen nemo.export.
- LLM-distribution överview
- Distribuera NeMo Large Language Models med NIM
- Distribuera NeMo stora språkmodeller med TensorRT-LLM
- Distribuera NeMo Large Language Models med vLLM
Modeller som stöds
Stora språkmodeller
| Stora språkmodeller | Förträning & SFT | PEFT | Inriktning | FP8 utbildningskonvergens | TRT/TRTLLM | Konvertera till och från kramande ansikte | Utvärdering |
|---|---|---|---|---|---|---|---|
| Lama3 8B/70B, Lama3.1 405B | Ja | Ja | x | Ja (delvis verifierad) | Ja | Både | Ja |
| Mixtral 8x7B/8x22B | Ja | Ja | x | Ja (ej verifierad) | Ja | Både | Ja |
| Nemotron 3 8B | Ja | x | x | Ja (ej verifierad) | x | Både | Ja |
| Nemotron 4 340B | Ja | x | x | Ja (ej verifierad) | x | Både | Ja |
| Baichuan2 7B | Ja | Ja | x | Ja (ej verifierad) | x | Både | Ja |
| ChatGLM3 6B | Ja | Ja | x | Ja (ej verifierad) | x | Både | Ja |
| Gemma 2B/7B | Ja | Ja | x | Ja (ej verifierad) | Ja | Både | Ja |
| Gemma2 2B/9B/27B | Ja | Ja | x | Ja (ej verifierad) | x | Både | Ja |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Ja | Ja | x | Ja (ej verifierad) | x | x | Ja |
| Phi3 mini 4k | x | Ja | x | Ja (ej verifierad) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Ja | Ja | x | Ja (ej verifierad) | Ja | Både | Ja |
| StarCoder 15B | Ja | Ja | x | Ja (ej verifierad) | Ja | Både | Ja |
| StarCoder2 3B/7B/15B | Ja | Ja | x | Ja (ej verifierad) | Ja | Både | Ja |
| BERT 110M/340M | Ja | Ja | x | Ja (ej verifierad) | x | Både | x |
| T5 220M/3B/11B | Ja | Ja | x | x | x | x | x |
Vision språkmodeller
| Vision språkmodeller | Förträning & SFT | PEFT | Inriktning | FP8 utbildningskonvergens | TRT/TRTLLM | Konvertera till och från kramande ansikte | Utvärdering |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | Ja | Ja | x | Ja (ej verifierad) | x | Från | x |
| Llama 3.2 Vision 11B/90B | Ja | Ja | x | Ja (ej verifierad) | x | Från | x |
| LLaVA Next (LLaVA 1.6) | Ja | Ja | x | Ja (ej verifierad) | x | Från | x |
Inbäddningsmodeller
| Inbädda språkmodeller | Förträning & SFT | PEFT | Inriktning | FP8 utbildningskonvergens | TRT/TRTLLM | Konvertera till och från kramande ansikte | Utvärdering |
|---|---|---|---|---|---|---|---|
| SBERT 340M | Ja | x | x | Ja (ej verifierad) | x | Både | x |
| Lama 3.2 Inbäddning 1B | Ja | x | x | Ja (ej verifierad) | x | Både | x |
World Foundation Models
| World Foundation Models | Efterträning | Accelererad slutledning |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | Ja | Ja |
| Cosmos-1.0-Diffusion-Text2World-14B | Ja | Ja |
| Cosmos-1.0-Diffusion-Video2World-7B | Kommer snart | Kommer snart |
| Cosmos-1.0-Diffusion-Video2World-14B | Kommer snart | Kommer snart |
| Cosmos-1.0-Autoregressiv-4B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-5B | Kommer snart | Kommer snart |
| Cosmos-1.0-Autoregressiv-12B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-13B | Kommer snart | Kommer snart |
Notera
NeMo stöder också förträning för både diffusions- och autoregressiva arkitekturer text2world grundmodeller.
Tal AI
Att utveckla konversations-AI-modeller är en komplex process som involverar att definiera, konstruera och träna modeller inom särskilda domäner. Denna process kräver vanligtvis flera iterationer för att nå en hög nivå av noggrannhet. Det involverar ofta flera iterationer för att uppnå hög noggrannhet, finjustering av olika uppgifter och domänspecifika data, säkerställande av träningsprestanda och förbereda modeller för slutledningsinstallation.
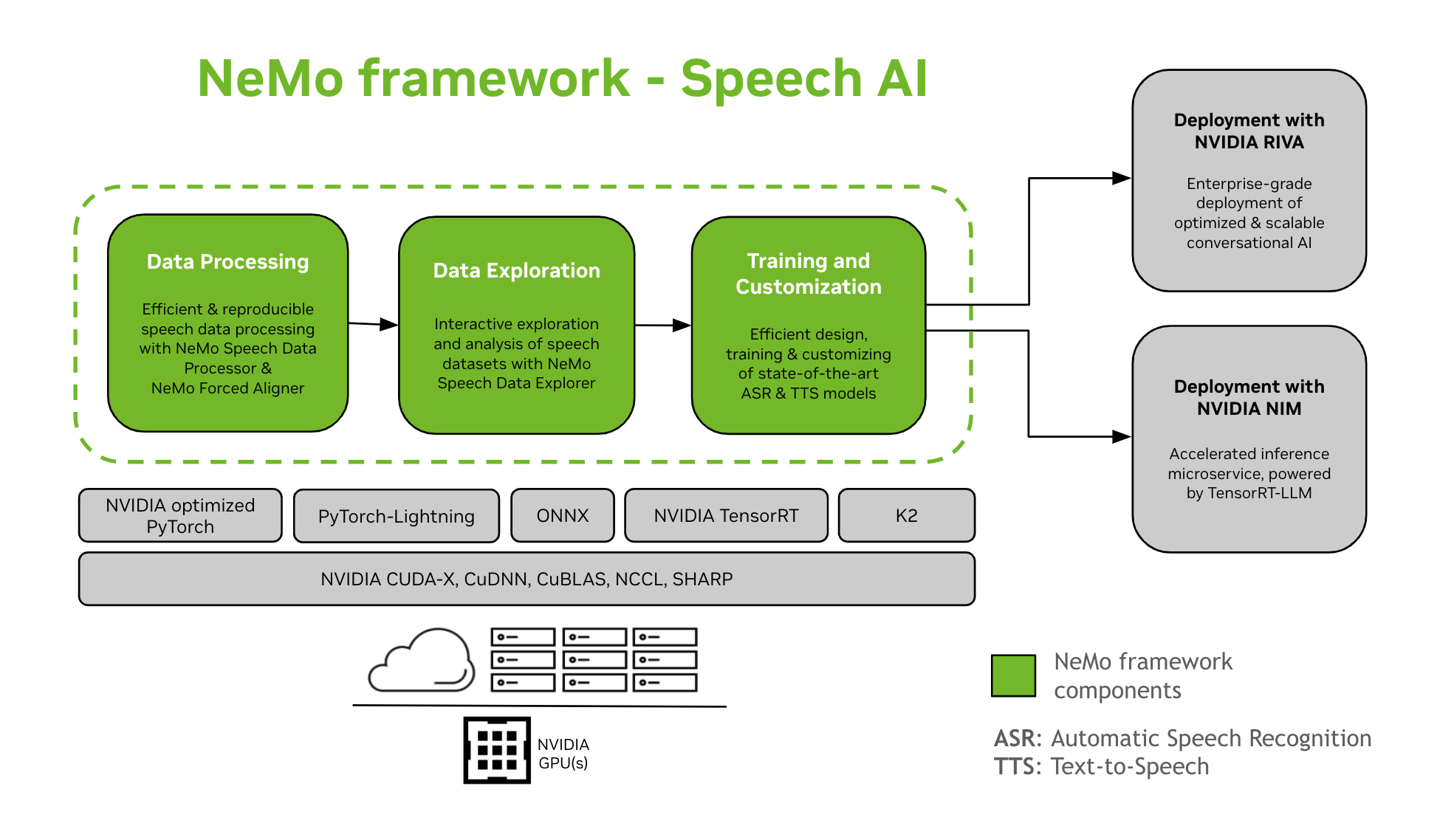
NeMo Framework ger stöd för utbildning och anpassning av Speech AI-modeller. Detta inkluderar uppgifter som Automatic Speech Recognition (ASR) och Text-To-Speech (TTS) syntes. Det erbjuder en smidig övergång till produktionsdistribution på företagsnivå med NVIDIA Riva. För att hjälpa utvecklare och forskare inkluderar NeMo Framework toppmoderna förutbildade kontrollpunkter, verktyg för reproducerbar taldatabearbetning och funktioner för interaktiv utforskning och analys av taldatauppsättningar. Komponenterna i NeMo Framework for Speech AI är följande:
Utbildning och anpassning
NeMo Framework innehåller allt som behövs för att träna och anpassa talmodeller (ASR, Talklassificering, Högtalarigenkänning, Speaker Diarization, och TTS) på ett reproducerbart sätt.
SOTA förutbildade modeller
- NeMo Framework tillhandahåller toppmoderna recept och förutbildade kontrollpunkter av flera ASR och TTS modeller, samt instruktioner om hur man laddar dem.
- Talverktyg
- NeMo Framework tillhandahåller en uppsättning verktyg som är användbara för att utveckla ASR- och TTS-modeller, inklusive:
- NeMo Forced Aligner (NFA) för att generera tidmätare på token-, ord- och segmentnivåamptal i ljud med hjälp av NeMos CTC-baserade modeller för automatisk taligenkänning.
- Taldataprocessor (SDP), en verktygslåda för att förenkla behandling av taldata. Det låter dig representera databehandlingsoperationer i en konfiguration file, minimerar boilerplate-kod och tillåter reproducerbarhet och delbarhet.
- Speech Data Explorer (SDE), en Dash-baserad web applikation för interaktiv utforskning och analys av taldatauppsättningar.
- Datauppsättningsverktyg som ger funktionalitet för att anpassa långt ljud files med motsvarande transkript och dela upp dem i kortare fragment som är lämpliga för Automatic Speech Recognition (ASR) modellträning.
- Jämförelseverktyg för ASR-modeller att jämföra förutsägelser av olika ASR-modeller på ordnoggrannhet och uttalsnivå.
- ASR utvärderare för att utvärdera prestandan hos ASR-modeller och andra funktioner såsom Voice Activity Detection.
- Verktyg för textnormalisering för att konvertera text från den skrivna formen till den talade formen och vice versa (t.ex. "31:a" vs "trettioförsta").
- Väg till implementering
- NeMo-modeller som har tränats eller anpassats med NeMo Framework kan optimeras och distribueras med NVIDIA Riva. Riva tillhandahåller containrar och Helm-diagram speciellt utformade för att automatisera stegen för tryckknappsinstallation.
Andra resurser
- NeMo: Huvudarkivet för NeMo Framework
- NeMo–Sikt: Ett verktyg för att konfigurera, starta och hantera dina maskininlärningsexperiment.
- NeMo-Aligner: Skalbar verktygslåda för effektiv modellanpassning
- NeMo-kurator: Skalbar dataförbearbetning och kuratorverktygssats för LLM:er
Engagera dig med NeMo-communityt, ställ frågor, få support eller rapportera buggar.
- NeMo-diskussioner
- NeMo-problem
Programmeringsspråk och ramar
- Pytonorm: Huvudgränssnittet för att använda NeMo Framework
- Pytorch: NeMo Framework är byggt ovanpå PyTorch
Licenser
- NeMo Github repo är licensierad under Apache 2.0-licensen
- NeMo Framework är licensierat under NVIDIA AI PRODUCTAVTAL. Genom att dra och använda behållaren accepterar du villkoren för denna licens.
- NeMo Framework-behållaren innehåller Llama-material som regleras av Meta Llama3 Community License Agreement.
Fotnoter
För närvarande är stöd för NeMo Curator och NeMo Aligner för multimodala modeller ett pågående arbete och kommer att finnas tillgängligt mycket snart.
FAQ
F: Hur kan jag kontrollera om mitt system påverkas av sårbarheten?
S: Du kan kontrollera om ditt system påverkas genom att verifiera versionen av NVIDIA NeMo Framework som är installerad. Om det är under version 24 kan ditt system vara sårbart.
F: Vem rapporterade säkerhetsproblemet CVE-2025-23360?
S: Säkerhetsproblemet rapporterades av Or Peles – JFrog Security. NVIDIA erkänner deras bidrag.
F: Hur kan jag ta emot framtida säkerhetsbulletiner?
S: Besök sidan för NVIDIA Product Security för att prenumerera på säkerhetsbulletiner och hålla dig informerad om produktsäkerhetsuppdateringar.
Dokument/resurser
 | NeMo Framework |
Referenser
- Användarmanualmanual.tools